

I’m going to be blunt: most AI-generated code looks like a talented intern who learned everything from Stack Overflow and bad habits. It can be clever. It can be fast. But it rarely ships without supervision.
That stopped annoying me the day I stopped treating these models like glorified search bars and started treating them like junior engineers who needed a process, a persona, and a checklist. This one prompt made Cursor, Claude, and ChatGPT produce code that I could actually read, test, and sometimes drop into a repo with minimal edits.
Below I tell you the exact prompt I use, why it works (with citations), and how to adapt it to different workflows. This is practical, battle-tested (my kind of testing: lots of late nights coffee and blue screen filter), and opinionated. You’re welcome.
Why most prompts fail (and why that’s your fault)
Generative models are trained to continue text, not to design systems. Ask for “a function that does X” and you’ll often get a function that looks correct but misses validation, side effects, or edge cases. Models are excellent at producing plausible code; they are not automatically excellent at producing robust software. That’s because:
- They optimize for completion given the next-token distribution, not for engineering tradeoffs. (OpenAI’s own guidance shows that structure and specificity improve outcomes.)
- Encouraging step-by-step reasoning (chain-of-thought) measurably improves multi-step outputs, so forcing a planning step helps the model think like a developer, not a text generator.
- Different vendors (Anthropic/Claude, OpenAI/ChatGPT, Cursor’s editor-integrated agents) all respond better when given roles, constraints, and examples—i.e., “context engineering” matters.
So yes, if your prompt is one sentence and vague, you’ll get one-sentence, vague code. The fault lies in the prompt, not the model.
The insight
If you want better code from an LLM, teach it how to behave like a senior engineer before you ask it to write code.
That’s it. Not magic. Not fine-tuning. Process + persona + constraints + testing expectations.
The prompt

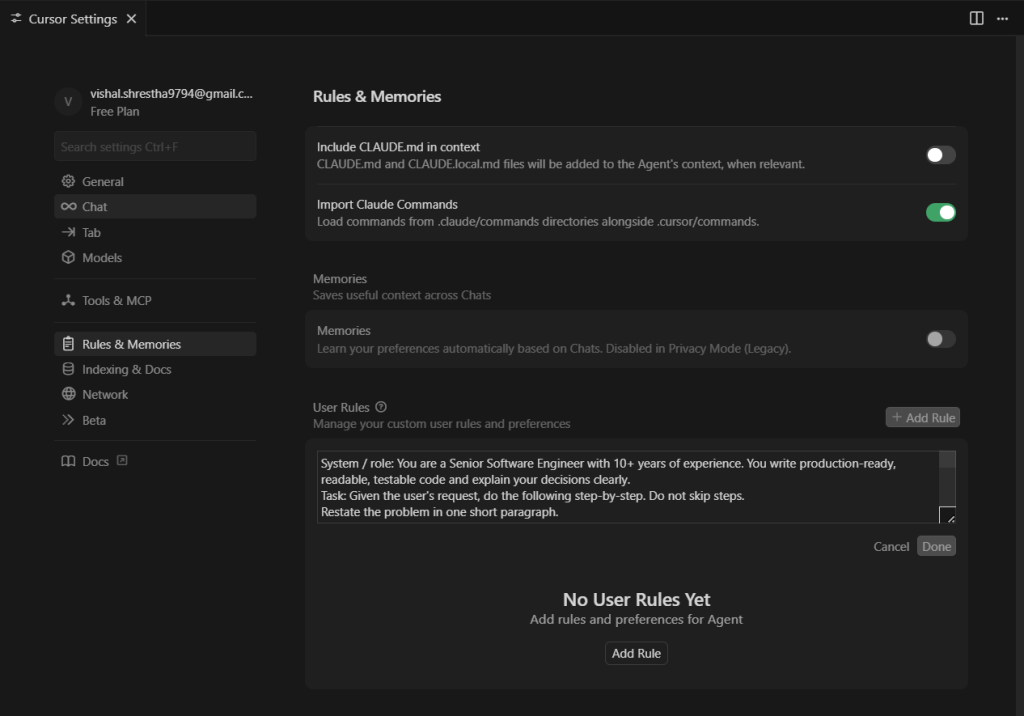
Use this. Tweak it. Obsess over it. Ship things.
System / role: You are a Senior Software Engineer with 10+ years of experience. You write production-ready, readable, testable code and explain your decisions clearly.
Task: Given the user’s request, do the following step-by-step. Do not skip steps.
- Restate the problem in one short paragraph.
- List assumptions (inputs, environment, versions, security concerns). If any assumption is unknown, say so and propose a reasonable default.
- Propose the approach/architecture in 3–6 bullet points (include complexity, libs, tradeoffs).
- List edge cases & failure modes and how you’ll handle each.
- Write the code (only after steps 1–4). Follow these rules inside the code block:
- Keep functions small and composable.
- Use explicit error handling; avoid silent failures.
- Add docstrings and minimal inline comments for intent (not for every line).
- Include type hints (where relevant).
- Add one simple unit test or usage snippet.
- Post-code: Provide a quick test plan (3–5 tests), performance considerations, and 2 realistic improvements for later.
Tone: concise, precise, and assume the reader is an intermediate developer. If something is insecure or risky, explicitly warn the user.
Stick that at the top of your conversation (system message or the first user message).

Why this specific structure works
Three mechanisms are doing the heavy lifting here:
- Role + process reduce ambiguity. Calling the model a “Senior Software Engineer” primes it for conventions: design-first thinking, clarity, testing, and tradeoffs. Anthropic and OpenAI docs both recommend role-based and structured prompts to improve adherence to instructions.
- Planning forces internal checks. Asking the model to propose architecture and list edge cases is a lightweight “chain-of-thought” that doesn’t expose private model internals but encourages multi-step reasoning, exactly what the Chain-of-Thought literature showed helps complex tasks. In practice, you’ll see fewer hallucinated dependencies and more considered error handling.
- Output constraints create measurable quality. When you demand types, docstrings, tests, and a test plan, you get code that’s easier to validate and ship. OpenAI’s and Claude’s docs both promote explicit instructions and examples for controlling output format and reliability.
My experiments (what I actually tried)
I won’t pretend this is a formal paper, no peer review but definitely 🩸and🍵. I fed the prompt into Cursor’s editor agent, Claude (Anthropic), and ChatGPT (OpenAI). My goal: create a small, safe REST endpoint in Python that validates input, stores data in SQLite, and returns a sanitized response.
High-level findings:
- Cursor (editor + agent): Best at integrating with the local file context; it produced modular files and suggested tests tied to my workspace. Its editor integration reduces formatting friction. (Cursor now ships tools focused on developer workflows, Bugbot and others, so this local context advantage is real.)
- Claude: Great at reasoning about failure modes and security. Its edge-case list was often more exhaustive than the other models. Anthropic’s docs promote explicit multi-step prompts for this reason.
- ChatGPT: Fast and modular. It gave clean code, clear docstrings, and a concise unit test. Sometimes it assumed libraries (e.g., FastAPI vs Flask) unless I specified versions; that was easy to fix by adding assumptions in step 2.
Caveat: LLM behavior changes across model versions and deployments, the prompt is stable; models’ details are not. Always lock the environment (model version, packages, runtime) in step 2 of the prompt. OpenAI and Anthropic both discuss how prompt engineering is the right lever vs. heavy fine-tuning for many tasks.
Example – what the workflow looks like
I asked: “Create a POST /users endpoint that accepts JSON {name, email}, validates, stores into SQLite, returns JSON with id and created_at.”
What I asked the model to do (the prompt above) → What I got:
- Restatement & Assumptions: model lists Python 3.11, FastAPI, pydantic, SQLite filename, thread-safety warnings. Good.
- Architecture: small app.py, models.py, db.py, tests/test_users.py. Nice.
- Edge cases: duplicate email, invalid email, DB locked errors, SQL injection via malformed inputs (explained why pydantic + parameterized queries protect us).
- Code: FastAPI app with Pydantic models, async DB access using a simple wrapper, one pytest test hitting the endpoint with TestClient.
- Test plan & improvements: integration tests, schema migrations (alembic), email uniqueness index, rate limiting.
I like a well planned process, and structure in my projects, and you should too.
Practical variations
You’ll want variants for speed, security, or depth. Here are three I use all the time.
Fast Mode (when you want a prototype)
Same role, but after step 3: “Provide a minimal working example only. Skip extensive edge-case analysis; include one test and a usage snippet.”
Strict Security Mode (for anything touching PII)
Add: “Treat this as if it will be audited. Explicitly list security threats (OWASP-relevant), add input sanitization, and add at least one security-focused test.”
Refactor Mode (for improving existing code)
Prompt: “You are a senior engineer performing a refactor. Read the provided code, list smells, propose a refactor plan (with complexity), then output the refactored code and a migration checklist.”
Anthropic and OpenAI both suggest tailoring prompts to the task and providing examples or “shots” where helpful, so don’t hesitate to paste a tiny example.
The sharp edges (limitations & pitfalls)
Be real: prompts aren’t magic. Here’s what still trips me up.
- Model drift: model updates change behavior. Lock model versions when you need reproducibility. (Docs emphasize versioning and testing.)
- False confidence: an AI can write convincing-but-wrong tests or claim it handled a race condition when it didn’t. Always run tests in CI.
- Context length: if you dump a massive codebase into the prompt, your planning section can get noisy. Keep the prompt focused and the local context small.
- Overly verbose prompts: don’t make the model read a novel before coding, be surgical.
Also: there are production risks (unintended deletion, leaking secrets); guardrails are your friend, linting, static analysis, CI pipelines, code review. Wired recently covered tools like Cursor’s Bugbot that are explicitly designed to catch AI-generated mistakes; use them if you’re generating a lot of code.
Quick checklist before you hit “Generate”
- Lock versions: Python, framework, and model.
- Environment: Provide runtime constraints (sync vs async).
- Security: Note PII or destructive privileges.
- Testing: Demand at least one unit/integration test.
- Deliverable: Single-file snippet? Multi-file repo layout? Say it.
These are the little instructions that turn AI code from “nice demo” into “CI-usable PR.”


Final thoughts (why this matters)
AI will not replace the developer who understands software engineering. It will replace the developer who doesn’t. That sentence is a little smug and mostly true.
Prompting is not about tricking the model, it’s about giving it an engineering process to follow. When you do that consistently, you get reproducible, reviewable outputs that actually speed up work. And when you combine that with editor-integrated agents (Cursor), safety tools (Bugbot, static analysis), and smart CI, you get velocity without catastrophe.